














- Energy & Environment
After nearly four decades as the “factory of the world,” China today is stepping into a new role in the global economy: as a hub for innovative applications of artificial intelligence. According to one recent study by PriceWaterhouseCoopers, of the $15.7 trillion in global wealth AI is expected to generate by 2030, a full $7 trillion will occur in China alone.
Why did China quickly vault into the top tiers of nations in artificial intelligence (AI)? And what implications will this have for the Chinese and the global economy? These are the questions we seek to answer here. That answer will come in three parts: the nature of recent advances in AI, the way these advances mesh with the particular strengths of China’s technology ecosystem, and the economic impact of the AI applications.
In the first section, we will argue that recent advances in AI constitute a transition from an age of discovery to an age of implementation. In the second section, we will show how that transition to AI implementation plays to certain strengths in China’s technology ecosystem and also deemphasizes some of that ecosystem’s inherent weaknesses. Finally, in the third section, we will propose a set of conceptual building blocks for analyzing the economic implications of artificial intelligence in China, in the United States, and around the globe.
Both artificial intelligence and China are topics far too expansive and multi-faceted for any one piece to cover in their entirety. There are myriad political, social and ethical questions stemming from artificial intelligence in China, but we will leave these for future discussion. We hope only that the following piece provides a framework for understanding the space where China, AI, and economics intersect.
I. The Nature of Recent Advances: From Discovery to Implementation
Understanding China’s rise in AI begins with a sound understanding of the technology itself, and where its development stands today. Today the flurry of headlines around AI is both heightening public excitement (and fear) around the technology, but also obscuring how the version of AI in use today works.
Traditionally, artificial intelligence has been a field of computer science concerned with building computer systems that can perform tasks usually reserved for humans: perceiving and interpreting the world around us, predicting outcomes clouded by uncertainty, and making complex decisions. Over the years, researchers debated and experimented with different approaches to constructing these AI systems. Should they code our existing knowledge into computers (an approach often called “expert systems”)? Or use software to imitate the process by which our own brains learn, and then let the computers learn for themselves (an approach now called “neural networks”)?
Debate between these camps raged for decades within academia, and while many new and exciting discoveries were made by researchers on both sides, the real-world impact of these discoveries remained limited. Throughout the 1980s and 1990s, top international researchers were able to create AI programs that performed certain highly specific tasks: synthesizing robotic-sounding speech, reading the numbers written on a check, or even playing chess better than a grandmaster. But these AI systems often weren’t generalizable enough to be of much use to companies. During this era, the center of gravity in AI remained in the laboratory, and the field remained in an age of discovery.
That all began to shift around a decade ago. Early applications of neural networks had often run up against two problems: a shortage of data on which to learn from or limitations in the complexity of the patterns they could spot. Driving that shift were two major changes: an explosion in digital data generated by the internet and the creation of an innovative approach to neural networks known as “deep learning.” The explosion in digital data from the internet captured many human activities (reading, watching videos, socializing, etc.) in a format that computers could process. The creation of deep learning gave AI systems a better way to learn from that data, empowering them to spot subtle correlations between different data points.
Deep learning’s ability to pick out incredibly subtle patterns within oceans of data is what powers AI applications today. Neural networks powered by deep learning are fed streams of digital data (credit card purchases, pictures of faces, driving records) and then use their superhuman pattern spotting abilities to predict the best answers to important questions (Is that purchase fraudulent? Whose face is that? Swerve right or brake?).
While a human brain tends to focus on the most obvious correlations between the input data and the outcomes, a deep learning algorithm trained on enough data will discover connections between obscure features of the data that are so subtle or complex we humans cannot even describe them logically. No single one of those connections or features can correctly predict an outcome, but when you combine hundreds or even thousands of them together, they can outstrip the performance of even the most experienced humans.
Concretely, these superhuman abilities of pattern analysis have given computers two new powers: the power of perception and the power of complex (non-linear) decision-making. For perception, where “dumb” digital devices could merely capture and reproduce images or sounds, “smart” AI programs can now identify and understand the content within those images and sounds. For complex decision-making, AI programs are no longer limited to binary “if-then” rules coded by a human, but can instead learn a far more flexible set of rules based on what they find in the data. Combining these powers with software (computer programs) and hardware (robotics) allows AI to take over countless tasks across society: driving a car, diagnosing a disease, assembling a sneaker, or making a mortgage loan.
With deep learning and the data explosion as catalysts, AI has moved from the age of discovery to the age of implementation. Research into frontier areas of AI continues at a furious pace, and discoveries in these areas may yet unlock vast new possibilities. But for now, at least, the center of gravity has shifted from elite research laboratories to real world applications. In essence, deep learning and data have boosted AI up onto a new plateau. Companies and governments are now exploring that plateau, looking for ways to apply present AI capabilities to their activities, to squeeze every last drop of productivity out of this groundbreaking technology.
Google CEO Sundar Pichai has compared the power of AI to humankind’s harnessing of fire. Analogies on that scale are inherently speculative and necessarily imprecise, but they can also be illustrative. If AI is fire, then the age of discovery is the period in which humans slowly, steadily learned the methods for generating a spark and capturing it in the form of a flame. The age of implementation is the era in which humans learned to apply that flame to all the tasks in their life: cooking food, staying warm, fighting wars, burning underbrush to open up land, and creating elaborate paintings within the darkness of a cave. These implementations of fire are analogous to the rapid exploration and commercialization of AI today: the self-driving cars rolling out on our streets, the AI-powered research into cancer treatments, the cashier-less Amazon Go stores, and the autonomous robots scurrying about our warehouses.
II. The Ingredients of AI Implementation: Research Talent, Data, Company Ecosystem, and Government Policy
The transition from discovery to implementation also has momentous implications for the drivers of AI progress, and thus which countries are likely to lead the world in AI applications. AI today can be thought of as containing four key ingredients: research talent, data, a company ecosystem, and government policy. (Semiconductors are also a key AI ingredient, though due to the technical complexity and high level of uncertainty regarding their development trajectory, we will set them aside for the purposes of this analysis.) The transition from an age of discovery to an age of implementation is reordering the relative importance of each of these ingredients and also alters what kind of talent, data, or corporate ecosystem is most likely to drive progress.
In the paragraphs below, we will examine China’s strengths and weaknesses in each of these four ingredients—research talent, data, company ecosystem, and government policy—and from that analysis propose an answer to our first question: why did China quickly vault to the top rank of nations in artificial intelligence? We will show that while China is by no means guaranteed leadership in all fields of AI, the transition from discovery to implementation will on balance highlight some of China’s comparative strengths, and deemphasize some of its weaknesses.
Research Talent
In an age of discovery, a nation’s AI prowess is determined primarily by the quality of a small group of elite researchers: the best-of-the-best academic talent who can push the boundaries of knowledge outward. But as the center of gravity in AI moves from research in the lab (discovery) to the building of commercial applications (implementation), it brings with it an analogous transition away from prizing the quality of elite researchers and toward prizing the quantity of competent engineers: the number of people who can take the research breakthroughs and apply them across hundreds of different industries.
The United States undoubtedly holds an advantage in the quality of its top-notch researchers. Our subjective analysis of the field concludes that virtually all of the top ten, and a large majority of the top one-hundred, AI researchers around the globe are located in the US or Canada, and are affiliated with US institutions. This is why many US institutions led the way in the age of discovery, and why they entered the age of implementation with a substantial lead over their international peers.
But as activity shifts to commercial applications, that leadership is no longer guaranteed. Chinese researchers have yet to produce research breakthroughs on the scale of deep learning, but they make up an increasingly large share of productive AI researchers and engineers.
A study conducted by Sinovation Ventures found that between 2006 and 2015 publications in the top one hundred AI journals and conferences by authors with Chinese names nearly doubled from 23.2 percent to 42.8 percent. These percentages include some international researchers with Chinese names—Chinese Americans who haven’t adopted an anglicized name, for example—but a scan of the researchers’ institutions validates that a large majority of them are working in China today.
That study only charted progress through 2015, a year before AlphaGo’s historic Go match against Lee Sedol and then Chinese world champion Ke Jie. Those matches have been likened to China’s “Sputnik moment” on AI, a turning point that helped set China on the path to becoming an AI superpower by firing the public imagination and inspiring young scientists to redouble their efforts. That public excitement has nudged thousands more Chinese computer science graduate students into pursuing artificial intelligence research.
This is the pool of talent that an age of implementation thrives on: the computer science Ph.D.’s who aren’t in line for a Nobel Prize, but who could easily transition into being the Chief Technology Officer of an AI startup or a product lead at a large company like Google or Baidu. As these implementers fan out across the country’s AI ecosystem, they will bring the power of AI to bear on hundreds of new problems, generating value for their employers and driving economic growth for China as a whole.
It’s worth noting that there are potential events that could bring this current era of deep-learning-driven implementation to an end. If researchers were to make another breakthrough on the scale of deep learning—a new approach that dramatically increases the power of algorithms to understand and learn—then it could precipitate a temporary return to an age of discovery. The center of gravity would once again return to research labs, and the United States’ advantage in best-of-the-best research could once again grant it a major advantage in AI development. How long that advantage held would depend on whether the discovery were to come out of academia (and thus be openly published) or occur within the confines of a company like Google, where trade secrets could keep the knowledge bottled up for longer before it disseminated to the international research community.
But for now, at least, the current age of implementation appears well-suited to China’s strengths in research: large quantities of highly-skilled, though not necessarily best-of-best, AI researchers and practitioners.
Data
The transition to the age of implementation has also dramatically increased the value of the second AI ingredient: data. Data can be viewed as the raw material on which AI runs, analogous to oil’s role in powering an industrial economy. As an AI algorithm is fed more training data—past examples of the phenomenon you want the algorithm to understand—it gains greater and greater accuracy. The more faces you show a facial recognition algorithm, the fewer mistakes it will make in recognizing your face; the more medical records you show to a diagnostic algorithm, the more accurate its predictions will be on whether a new patient has cancer. Generally speaking, an algorithm designed by competent (but not outstanding) researchers that is fed large volumes of training data will outperform an algorithm crafted by the world’s best AI scientists, but trained on less data.
This link between data and real-world performance has been true for decades, but in the age of discovery it did not matter nearly as much. The inability to commercialize the current state of the art meant that the field focused on academic publications, which often require novel approaches to algorithm design in order to pass peer review. Simply achieving better performance on an existing algorithm by supplying it with greater data is not enough to get an academic paper published.
But it is enough to generate a superior product in the marketplace. With those commercial products now made possible by deep learning, data has become one of the most precious resources of an AI company. Relatively speaking, this tilts the playing field away from those companies with the most elite research talent, and towards those companies with the largest stockpiles of user data.
At first glance, it’s not immediately clear whether this shift to data-driven AI implementation would aide companies from China or the United States. Companies from both countries have different strengths when it comes to data, strengths that can be understood better if we map the monolithic concept of “data” across three dimensions: breadth, quality, and depth.
Breadth refers to the number of users of a given service, the population whose actions are captured in data. Quality refers to how well-structured and well-labeled the data is. Using medical diagnostic data as an example: is that data already formatted into uniform Excel documents easily readable by an AI algorithm, or stored on slips of paper across thousands of different filing systems? And was the human-made diagnosis that the algorithm is learning from correct in the first place? Finally, depth refers to how many different data points are generated about the activities of each user. In essence, how many different activities of a given user are captured in digital form that AI algorithms can learn from, allowing them to better predict a user’s needs.
On the first dimension, breadth, Chinese and American companies are on relatively even footing. While American internet companies have a smaller domestic user base than their Chinese peers, the most successful among them can also draw in users from around the globe, bringing their total user base to over a billion. Chinese companies have a much larger domestic population to draw on (1.1 billion mobile internet devices on 4G), and are now starting to make inroads with international users from Southeast Asia to South America.
On quality of data, American organizations enjoy a distinct advantage: companies and public institutions in the United States are much more likely to use enterprise software that structures their data for immediate use. Chinese corporations and public entities are moving in this direction, in part due to increased bureaucratic incentives for utilizing data. Still, they lag substantially behind US organizations in terms of accumulation of AI-ready data.
But on depth of data, China has the upper hand. Compared with their American peers, Chinese internet users funnel a much larger portion of their daily activities, transactions, and interactions through their smartphones. They use their smartphones to buy vegetables at the market, manage their social security, pay their water bills, book bus tickets, take out loans, and so much more.
Some of this is due to a leapfrog effect. While the slow-and-steady development trajectory of the US has led to an accumulation of legacy systems, China’s high-speed development skipped many steps. Chinese consumers never embraced credit cards, and so they jumped straight from an all-cash economy to using their smartphones for mobile payments at real-world outlets. Similar leaps have led to more rapid adoption of digital sharing economy services, with Chinese users accounted for a full 68 percent of rides on shared bikes and ride-hailing services.
Weaving together these different strands of data—mobile payments, public services, financial management, shared mobility—gives Chinese technology companies a deep and multi-dimensional picture of their users, one that allows their AI algorithms to precisely tailor product offerings to each individual. This will prove highly valuable in the manifold consumer applications of AI: offering mortgage loans, optimizing supply chains, and operating automated supermarkets and convenience stores that can predict what, when and where each product is needed. In the current age of AI implementation, this will likely lead to a substantial acceleration and deepening of AI’s impact across the Chinese economy.
Company Ecosystem
The corporate technology ecosystems of the United States and China are united by several characteristics: unmatched size, parallel funding structures, analogous product verticals, and high innovative capacity. But when it comes to the cultural norms that animate these ecosystems, they diverge in substantial ways that will impact the speed and the nature of AI adoption. Most notable among these cultural differences is the attitude toward imitating, iterating, and rapidly scaling successful business models pioneered by others.
For illustrating this divide, it’s useful to introduce an analytical framework popularized by Peter Thiel: the difference between “0 to 1” and “1 to n” innovation. Zero to 1 innovation describes the process of creating original and radically new products or services. By contrast, 1 to n innovation involves scaling up and iteratively improving an existing offering. This clean dichotomy is inherently reductionist: no new products truly begin from “0,” and moving from “1 to n” is not the linear process implied by the title. But they do offer conceptual frames that are useful for understanding the unique cultural undercurrents of China and Silicon Valley.
Silicon Valley (and the US tech ecosystem more broadly) both prides itself on and excels at 0 to 1. In US tech circles, there is great prestige attached to outside-the-box thinking, and significant levels of stigma for those who merely imitate existing models. As a result, the US ecosystem carries a more significant first-mover advantage, allowing the pioneers of a model to patiently harvest the low-hanging fruit borne out of their original idea.
China’s technology ecosystem, by contrast, tends to excel at the 1 to n part of the innovation equation. Chinese tech entrepreneurs are far more cautious when it comes to experimenting with radically new ideas, but they have no hesitation when it comes to imitating and improving on a successful business model. The reasons for this are complex, including everything from millennia-old cultural traditions, to the breakneck pace of economic development in recent decades. But the results are clear: when a new technology or business model is proven to work, dozens or even hundreds of Chinese startups flood into that industry and compete ferociously for dominance.
What happens next can best be compared to evolutionary natural selection. Hundreds of organisms (startups) of the same species (business model) scratch and claw for scarce resources (users and venture capital funding), differentiating themselves through subtle genetic mutations (tweaks to models or increased operational efficiency). The vast majority of these organisms perish, while those with mutations that bring in more users and capital survive to fight another day.
At a corporate level, this process doesn’t necessarily reward the most original companies but rather those that are the best at iterating and executing. At a systemic level, this process is extremely effective at exploring and exploiting hundreds of different applications of a new technology or business model. With none of Silicon Valley’s deference for first-movers, the pace of 1 to n innovation is accelerated, and many more branches of the genetic tree are explored.
In the past decade, we’ve witnessed this process play out time and again in China with the advent of the mobile internet, sharing economy, online-to-offline commerce, live streaming, and many more sectors. In each of these sectors, it’s proven to be a process optimized for fast execution, risk taking, and incredibly thorough exploitation of profitable applications.
At the same time, that process can be ugly and, looked at in a narrow sense, wasteful. It produces many copycats and fewer radically new innovations. Hundreds of millions of labor hours and venture capital dollars are spent on nearly identical companies, the majority of which won’t survive. But when the potential upside of a new industry or technology is large enough, the results can be just as awe-inspiring as the introduction of a radically new 0 to 1 idea.
What does this all have to do with AI? The 0 to 1 innovation that Silicon Valley excels at meshed well with the age of AI discovery, while China’s focus on 1 to n is ideal for exploiting all the manifold possibilities of the age of AI implementation. With the discovery of deep learning behind us, the most immediate economic question becomes how will AI’s powers of optimization-via-data be applied to different tasks and industries. By cultural inclination and ecosystem dynamics, China appears primed to mine this technology for all it’s worth.
As noted above, these categories—“0 to 1,” “1 to n,” “original,” “copycat”—are inherently reductive and in no way capture the full complexity of either ecosystem. Many American startups have few qualms about imitation and display similar competitive instincts to their Chinese peers. The 2018 rush into scooter-sharing startups has echoes of the Chinese competitive model, and was in fact inspired by Chinese success in bike-sharing. Similarly, some Chinese companies have demonstrated remarkable creativity and originality in their products and business models. Tencent’s WeChat long ago transformed from a simple chat app to a globally unique super-app, and Alibaba’s City Brain project has the potential to introduce a radically original vision of AI-powered urban infrastructure management.
But as a broad framework for mapping the strengths and weaknesses of these two ecosystems onto the current phase of AI development, we believe this dichotomy holds valuable explanatory and predictive power. While the Chinese technology ecosystem has many weaknesses, its strengths are particularly suited to maximizing the economic potential unleashed during the age of AI implementation.
Government Policy
The role of government policy in driving China’s progress in AI is both widely remarked upon and widely misunderstood. Those misunderstandings often fall into two differing conceptions of the primary mechanism by which the Chinese government drives AI development: picking winners that it showers with subsidies, or by issuing top-down commands dictating what technologies to create.
There are, of course, ways in which the government subsidizes certain AI companies and also instances in which China’s science and technology bureaucracy mobilizes to develop certain technologies. On subsidies, the government actively incentivizes private venture capital (VC) investment in AI through “guiding funds,” a clever financial structure by which the public funds are used guide funds into certain sectors by increasing the upside for private VC investors without removing the risk for them. In terms of top-down directives, China’s Ministry of Science and Technology has set ambitious and highly specific targets for the performance of indigenously produced AI chips, and it is pouring major resources into achieving those goals.
These efforts are real, and they both stimulate and, in some cases, distort China’s private sector AI development. But as the age of AI implementation bears its most substantial fruit, subsidies and top-down commands will likely not be the government’s most impactful means of accelerating AI development. Instead, it will be the way that the central government’s AI development plan incentivizes local officials to work with private sector actors on adapting public infrastructure and accelerating public adoption of AI. Unpacking that mechanism requires drilling down further on the coming waves of AI implementation.
Our current phase of AI implementation has been deeply impacting certain industries for close to five years. The reason why this impact isn’t always obvious to the casual observer is that it has thus far been largely confined to data-driven companies in sectors such as the internet, finance, or insurance. Deep learning first made landfall in these sectors because the implementation can be handled entirely by the private sector: Alibaba needs no government cooperation to deploy AI in optimizing its ad choices, and Goldman Sachs doesn’t need to engage the White House to leverage big data analytics for its investment decisions.
But if AI is to expand its impact from the data-driven digital world into the physical world—via autonomous vehicles, medical AI, smart cities, etc.—it will likely require the proactive adaptation of public infrastructure, and proactive adoption by public entities. Accelerating deployment of autonomous vehicles may entail slight changes to public roads, such as embedding sensors or reserving separate lanes for pilot programs. Bringing AI’s benefits to the public education or healthcare spheres will require analogous tweaks to those systems. All of these changes will necessitate the creation of new regulatory frameworks, laws that can embody shared values of privacy or responsibility while harnessing the new possibilities unlocked by the technology. Each of these moves—adapting public infrastructure, adopting new technology tools, and piloting new forms of public-private cooperation—requires a certain degree of political risk, particularly in highly combative political systems.
This is where China’s “New Generation Artificial Intelligence Development Plan” will have some of its deepest impacts. Rather than representing a top-down blueprint for AI development, the plan functions above all as a signal, one that is broadcast to local officials throughout China’s sprawling bureaucracy. It imbues AI with a stamp of approval from the central government and the Chinese Communist Party, both de-risking and actively incentivizing local projects that make use of AI in some way.
The career trajectories of these officials are largely determined based on performance assessments, and an initiative as high-profile as the AI development plan can make AI promotion another metric on which these officials will be evaluated. If the AI projects these local officials push bear fruit, they will be rewarded. If those projects fail, the bureaucratic costs of that failure will be substantially lower given that they occurred within the framework of an officially sanctioned push for AI.
Which manifestations of AI these officials choose to adopt will largely depend on their role in the bureaucracy, as well as local economic structures. An agricultural official in southwestern China might look to push a pilot project using autonomous seeding drones at state-owned agricultural facilities. A mayor in a packed city might work with Alibaba to install the infrastructure for a City Brain project that optimizes traffic and emergency services using computer vision. A university president in a manufacturing region might establish a new public-private research institute focused on factory automation. Across the board, these local bureaucratic actors will employ a range of tools: public procurement, pilot projects, infrastructure adaptations, subsidies, and regulatory accommodation.
This combination of central government signaling and local government implementation is particularly suited to accelerating implementation of an “omni-use technology” like AI, one that can be directly applied to thousands of different tasks. No command-and-control structure or single blueprint could efficiently direct state resources toward exploiting all the manifold applications of AI. Likewise, throwing subsidies at every AI company across the economy would be wildly inefficient and ultimately unfeasible. But if this model of the AI plan plays out as intended, it could represent a powerful synergy of central direction and local flexibility.
This model of central signaling and local application could have other potential downsides as well. If AI ended up falling far short of current expectations of its economic impact, then directing this level of bureaucratic and financial resources toward maximizing its value could prove wasteful. But if the above arguments on the transition to the age of implementation hold—that is, no new breakthroughs are required to generate large economic returns from application—then we believe this outcome is unlikely. Many of the economic fruits of AI are already ripe, and it is largely a question of which ones require public sector adaptation or adoption to be picked. Substantial government involvement is by no means a prerequisite for technological leadership, but as AI seeps deeper into the real-world systems that surround us, that adaptation and adoption will likely accelerate the economic impact of the technology.
III. Economic Implications
The above sections have outlined our answer to the question of why China has so rapidly vaulted into the top tiers of AI powers worldwide. The following section will examine the economic impact of AI technology in China and elsewhere, with a focus on employment, inequality, and potential policy responses.
There is major debate within economics and policy circles over the pace and scope of jobs at risk of being replaced by AI-powered technology. Low-end estimates have pegged that number at just 9 percent, while other studies have placed it at 47 percent by the early 2030s. The reasons for that wide range of outcomes, and precise predictions of the percentage of jobs put at risk by AI, are beyond the scope of this paper. (For a detailed analysis and critique of these studies, see chapter six of AI Superpowers: China, Silicon Valley, and the New World Order. )
Instead, we will draw on the nature of the technology itself as a source for constructing key conceptual building blocks that can lay a foundation for further discussion. Specifically, we will look at what the functioning of AI can reveal about the kinds of jobs that are at risk, the impact on competition between firms, and how this maps onto the broader macroeconomic and geopolitical landscape.
Jobs
We have already described in general terms the key mechanisms behind deep learning-driven AI systems: using large quantities of training data to discover subtle correlations between inputs and outcomes, correlations that help the system make predictions of future outcomes with superhuman accuracy. While this mechanism can be incredibly powerful under certain conditions (abundant data, narrow goals, and clearly labeled outcomes), it also has limitations.
Specifically, AI today cannot perform well when there is insufficient digital training data on an activity, or when outcomes cannot be clearly quantified or categorized. For cognitive tasks, this means AI struggles at highly strategic or creative tasks with unclear goals, or highly social tasks that require a nuanced understanding of another person’s emotions. For physical tasks, AI-powered robots operate well in highly structured environments (factories, highways) but struggle with unstructured environments (messy homes) or tasks that involve high dexterity and a gentle touch.
Mapping these abilities and limitations in two-dimensions yields the following Risk-of-Replacement Charts for both cognitive and physical labor:
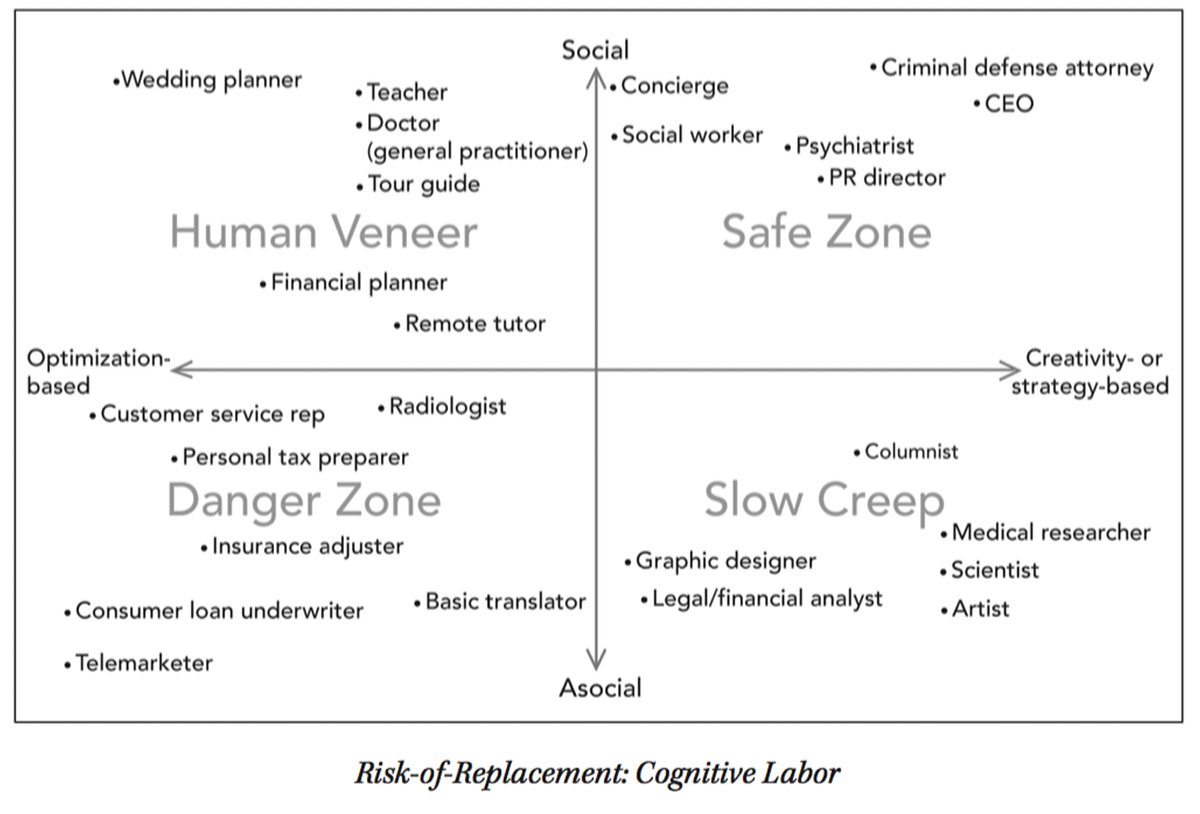
Each chart is broken down into four quadrants that will see different impacts from AI. In the bottom-left “Danger Zone” – jobs that are a-social and repetitive – humans have little advantage over AI, and we expect these jobs to be replaced on a long enough time horizon. In the “Human Veneer” quadrant of the upper left — repetitive and social — many of the core tasks may be taken over by AI, but there remains a social component that people will continue to perform. This quadrant may see reductions in total jobs, with a smaller number of workers providing that human interface.
The “Slow Creep” section is comprised of a-social jobs that remain beyond AI’s current narrow limits of strategy or dexterity. These are safe for the time being but are vulnerable to getting vacuumed up as AI expands its ability to multi-task. Finally, in the “Safe Zone” of the upper right-hand quadrant are jobs that remain well beyond AI’s current capabilities in terms of creativity, strategy, dexterity and sociability.
Clearly, this two-dimensional categorization of jobs is inherently reductionist, smoothing over great diversity of tasks within each profession, as well as the social and political structures that will protect certain occupations but not others. These are all very important factors that will affect the pace and scope of jobs lost to AI and are deserving of further examination. The above charts are merely offered as a conceptual framework for how AI’s technical capabilities map onto current professions and a starting point for a conversation on employment impact on AI.
Broadly speaking, they can also suggest the directions of a long-term workforce transition, one that could prove as momentous as the 19th and 20th century transitions from agriculture to manufacturing. In the context of these graphs, any skill transitions that move a worker up (more social) or to the right (more creative, strategic, or physically dexterous) are likely to increase their job security. Taken out to a macro level, this would indicate an economy-wide shift toward more care, service, and creative jobs. These would include not just high-education professions such as attorneys or therapists, but also nurses, coaches, and those who care for infants or the elderly.
Job Impacts in China and the US
As noted above, predicting the precise scale of jobs put at risk by AI is beyond the scope of this paper. Instead, we will offer up some conceptual building blocks for how the nature AI implementation and the distribution of occupations in the two countries will affect the pace and size of job losses.
Conventional wisdom holds that Chinese workers will be hit far harder by AI replacement, with China serving as “ground zero for the economic and social disruption brought on by the rise of the robots.” The argument here is straightforward. Nearly one half of Chinese workers are on farms or factories. They often perform highly repetitive tasks, and one main reason these factories are located in China is because of the country’s cheaper wages and large population. Once intelligent robots can perform those same tasks (for zero pay and operating 24 hours per day), the factories will leave China, saddling it with massive layoffs in the industrial sector. This story has an internal logic, and it matches with our what we’ve observed in the US this half century about what kinds of jobs get lost to automation: factory and farm jobs. We’ve also seen instances of this process at work already, with reports of Chinese electronics mega-factories replacing tens of thousands of workers with robots.
But this process may not be as speedy or disruptive as some predict. The reason behind that is often called Moravec’s Paradox: contrary to popular assumption, it’s easy for AI to mimic high-level intellectual or computation abilities, but far harder to give a robot the sensorimotor skills of a toddler. Some of this has changed since the Paradox was first articulated in the 1980s; robots have gotten far better about sensing the world around them but continue to have difficulty in manipulating objects with the dexterity of a human hand.
The result is that pure software applications of AI are far easier to create, free to instantly disseminate around the globe, and can be tweaked remotely with each new update. Robotics is a trickier business, requiring a complex interplay of mechanical and electrical engineering, perception AI, and fine-motor skill manipulation of objects. The products must then be constructed, shipped around the world, and often fixed by trained technicians on-site.
This has major implications for the sequence of AI induced job losses. While it may seem that China’s legions of factory workers are in immediate danger of unemployment, the many frictions of deploying functioning robotics across an economy may substantially slow that process down, giving the workers (or their children) time to integrate into more social or non-repetitive jobs.
US workers have their own sets of protections. Aside from protections for unionized employees, American workers also cluster more in service industries, from education to sales to public relations. Needed social skills such as persuasion or empathy will help to insulate them against immediate pressures from AI. At the same time, America’s own legions of middle-class, college-educated office workers, those whose jobs it is to take in data and make predictions about outcomes, face shakier prospects. Without a substantial social or strategic component to their work, workers in these occupations are at risk of being replaced by algorithms that are created easily, distributed freely, and updated remotely. Reports in June of 2018 that Citigroup executives were discussing replacing up to 10,000 of the company’s 20,000 operations and technology employees with machine learning in the next five years are testament to just how sweeping these changes could end up being.
Scanning the economic landscape of these two countries, it’s not clear which will experience deeper employment impacts from AI on a ten- to fifteen-year time scale. Both countries have large swaths of jobs that would be technically feasible to automate in the near future but also social and logistical buffers against that automation taking place immediately. The clearer divide emerges when we compare economic impacts not between the US and China, but when we look at the technology’s impacts on inequality on the individual, firm, and international levels.
The AI Inequality Machine
One notable characteristic of the above Risk-of-Replacement charts is the mix of jobs located in the upper-right “safe” quadrants: the occupations listed here tend to fall on the very high- or relatively low-earning end of the spectrum, with CEOs, home care workers, trial attorneys, and hair stylists all performing tasks that are outside of AI’s reach. While all of these jobs may appear “safe” for the time being, the rewards granted to each will be dramatically different: many CEOs will leverage AI against their existing capital and data resources to generate astronomical returns, while home care workers unable to leverage AI for their work will likely find themselves squeezed by competition from an ever-larger pool of similarly-skilled workers.
This points to another conceptual building block for understanding this economic impact: AI as a technology is inherently monopolistic, exerting a gravitational pull that concentrates profits in the hands of a few. This is what we call the “AI inequality machine,” and it occurs on multiple levels: individual jobs, firms, and countries. Driving this monopolization are self-reinforcing cycles of data accumulation, improved performance, and greater personalization for users. Data is one of the key ingredients in building effective AI, and it tends to enter one of these self-reinforcing cycles of accumulation: the more data you have, the better your AI product performs, the more users you draw in, the more data you have.
AI’s capacity for learning and thus tailoring its actions to each individual user also helps it escape a normal trade-off between scale and personalization in a product. For AI, the data offered by scale can actually mean greater personalization: algorithms trained on more data will actually be better trained to offer you exactly the product or experience that suits your own needs. The customer may experience this as the product simply “working better,” but it has major ramifications for firm-level competition across the economy. If left unchecked, it could further winnow down the number of competitive firms, establishing an oligopolistic system dominated by just a handful of companies.
On an international level, these dynamics are already taking hold. Today just a handful of companies have emerged as the AI giants, with virtually all of them based in the United States and China. This reflects existing concentrations in user data and engineering talent and major investments in AI that have given these giants a massive head start. If that growth goes unchecked, it’s possible that these firms leverage their existing advantage to branch out and dominate traditionally offline industries around the world: autonomous transportation, “dark factories” with no workers, cashier-less grocery stores and AI-driven medical care. If they did so, we would see improvements in products used by consumers but ever-greater concentration of profits in the hands of just a few companies in an even smaller number of countries.
Developing countries will face their own AI challenges. As automation of physical and cognitive tasks deepens across the global economy, it will pull away the bottom rungs of the ladder of economic development. Traditional development models in countries like China and India have relied on comparative advantages in low-wage manufacturing or English-language call centers to kickstart the development process. Moravec’s Paradox ensures these factory jobs aren’t disappearing overnight, but it’s unlikely we will see multinational corporations build extensive new supply chains in low-wage countries before putting that investment into automation. With these traditional development models closed off by intelligent machines, these countries will need to find new ways to claw themselves out of poverty in a world where both wealth and economic production are increasingly concentrated within an elite group of individuals, firms, and countries.
There exist several possible ways in which the global AI economy could change course. Perhaps European or American regulators will break up existing tech monopolies. Or maybe countries such as India will combine a large population, engineering talent, and localization advantages to build up AI giants that serve their domestic markets. Or, in a move that would lead to even greater consolidation, maybe a technique to supplant deep learning is invented and kept in-house at a place like Google, giving just one company an incalculable advantage over all others. At this point, we can’t predict which of these contingencies will come into play.
IV. Conclusion
The above article has attempted to construct key conceptual building blocks derived from the capabilities of AI technology itself. Those building blocks have included (1) AI’s transition from an age of discovery to an age of implementation; (2) the role of key ingredients such as research talent, data, company ecosystems, and government policy; (3) the powers and limitations of present-day AI, and how these interact with the employment landscape; (4) the role of Moravec’s Paradox in the sequence of employment impacts; and (5) the way AI’s tendency toward monopoly will affect individuals, firms, and countries.
Piecing together these building blocks, we sketched out several potential economic impacts deriving from the technology. These are by no means set in stone but are rather offered as starting points for discussions of how AI will impact economies both local and global. Our hope is that this discussion provides a solid foundation for exploring future trajectories of AI’s social and economic impacts. The AI revolution must not become another wedge driving inequality, but rather should be used to take better care of the most vulnerable, while sharing benefits broadly across society. We invite, and look forward to engaging with, further studies from a range of disciplines addressing AI’s impact on employment, inequality, and our shared communal bonds.
Kai-Fu Lee is the chairman and CEO of Sinovation Ventures and president of its Artificial Intelligence Institute. He is the former president of Google China. Matt Sheehan is a fellow at the Paulson Institute. They recently authored AI Superpowers: China, Silicon Valley, and the new world order.
1 Full $7 trillion: Dr. Anand S. Rao and Gerard Verweij, “Sizing the Prize,” PwC, June 27, 2017, https://www.pwc.com/gx/en/issues/analytics/assets/ pwc-ai-analysis-sizing-the-prize-report.pdf.
2Debate between these camps rage: Kaplan, Jerry. Humans Need Not Apply. Place of Publication Not Identified: Yale University Press, 2016.
3Shortage of data: Michele Banko and Eric Brill, “Scaling to very very large corpora for natural language disambiguation,” Proceedings of the 39th annual meeting on association for computational logistics, 2001, p. 26-33.
4Harnessing of fire: Catherine Clifford, “Google CEO: A.I. is more important than fire or electricity,” CNBC, February 1, 2018, https://www.cnbc.com/2018/02/01/google-ceo-sundar-pichai-ai-is-more-important-than-fire-electricity.html.
542.8 percent: Dr. Kai-Fu Lee and Paul Triolo, “China Embraces AI: A Close Look and a Long View,” Sinovation Ventures and The Eurasia Group, December 2017, https://www.eurasiagroup.net/files/upload/China_Embraces_AI.pdf.
6 “Sputnik moment”: Paul Mozur, “Beijing wants A.I. to be Made in China by 2030,” The New York Times, July 20, 2017, https://www.nytimes.com/2017/07/20/business/china-artificial-intelligence.html.
7Trained on less data: Michele Banko and Eric Brill, “Scaling to very very large corpora for natural language disambiguation,” Proceedings of the 39th annual meeting on association for computational logistics, 2001, p. 26-33.
81.1 billion mobile internet devices: “China has over 1.1 billion 4G mobile users,” China Daily, July 23, 2018, http://usa.chinadaily.com.cn/a/201807/23/WS5b558effa310796df4df8281.html.
968 percent of rides on shared bikes and ride-hailing: Mary Meeker, “Internet Trends 2018,” Kleiner Perkins, May 30, 2018, https://www.kleinerperkins.com/perspectives/internet-trends-report-2018.
10 Zero to 1 innovation: Thiel, Peter A., and Blake Masters. Zero to One: Notes on Startups, or How to Build the Future. London: Virgin Books, 2015.
11 Globally unique super-app: Connie Chan, “When One App Rules them All: The Case of WeChat and Mobile in China,” Andreesen Horowitz, August 6, 2015, https://a16z.com/2015/08/06/wechat-china-mobile-first/.
12 “Guiding funds”: Dr. Kai-Fu Lee, AI Superpowers: China, Silicon Valley and the New World Order, New YorK: Houghton Mifflin Harcourt, 2018. 64-65.
13 Just 9 percent: Melanie Arntz, Terry Gregory, and Ulrich Zierahn, “The Risk of Automation for Jobs in OECD Countries: A Comparative Analysis,” OECD Social, Employment, and Migration Working Papers, no. 189, May 14, 2016, http://dx.doi.org/10.1787/5jlz9h56dvq7-en.
14 Placed it at 47 percent: Carl Benedikt Frey and Michael A. Osborne, “The Future of Employment: How Susceptible Are Jobs to Automation,” Oxford Martin Programme on Technology and Employment, September 17, 2013, https://www.oxfordmartin.ox.ac.uk/downloads/academic/future-of-employment.pdf.
15 Detailed analysis and critique of these studies: Dr. Kai-Fu Lee, AI Superpowers: China, Silicon Valley and the New World Order, New YorK: Houghton Mifflin Harcourt, 2018. 158-163.
16 Chinese electronics mega-factories: Jane Wakefield, “Foxconn replaces '60,000 factory workers with robots,'” BBC News, May 25, 2016, https://www.bbc.com/news/technology-36376966.
17 Replacing up to 10,000: “Automation could thin Citigroup's investment banking unit jobs: FT” Reuters, June 11, 2018, https://www.reuters.com/article/us-citigroup-layoffs/automation-could-thin-citigroups-investment-banking-unit-jobs-ft-idUSKBN1J72IX.
