- Innovation
- Science & Technology
- Revitalizing American Institutions
Abstract:
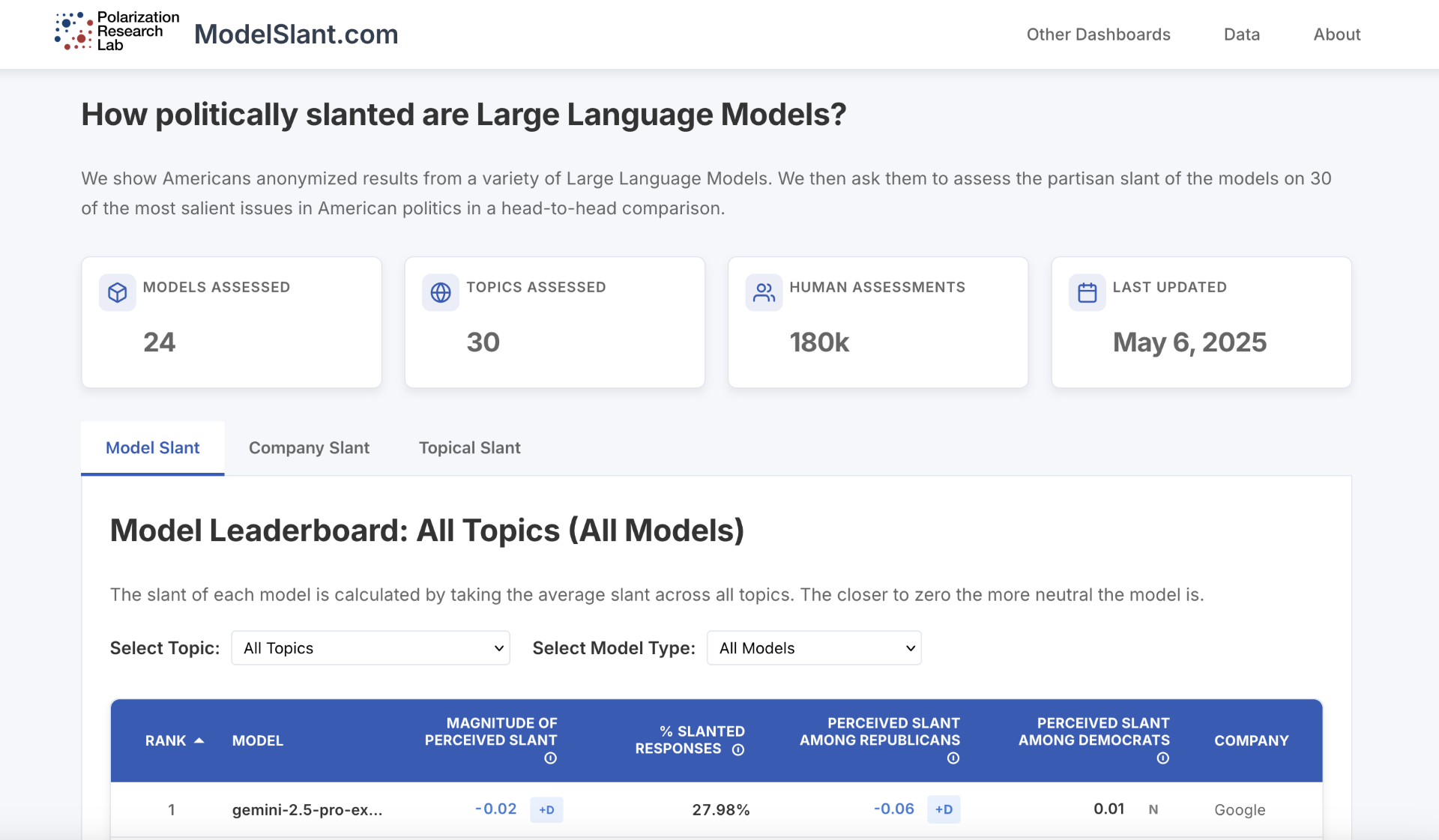
As large language models (LLMs) become the default interface for search, news, and everyday problem-solving, they may filter and frame political information before citizens ever confront it. Identifying and mitigating partisan "bias''—output with a systematic slant toward a political party, group, or ideology—is therefore a growing concern for researchers, policymakers, and tech companies. Existing methods often treat political slant as an objective property of models, but it may vary depending on the prompt, reader, timing, and context. We develop a new approach that puts users in the role of evaluator, using ecologically valid prompts on 30 political topics and paired comparisons of outputs from 24 LLMs. With 180,000 assessments from 10,007 U.S. respondents, we find that nearly all models are perceived as significantly left-leaning—even by many Democrats—and that one widely used model leans left on 24 of 30 topics. Our framework generalizes across users, topics, and model types, and also allows us to test interventions: when models are prompted to adopt more neutral stances, users perceive less slant and report more interest in using the model in the future, on average.
Significance Statement:
Large language models increasingly act as gatekeepers of political information, yet their ideological leanings remain poorly understood. Most existing audits use automated probes that overlook how real users perceive bias. We develop a scalable, user-centered metric that makes people—not algorithms—the arbiters of partisan slant. Drawing on 180,126 pairwise judgments of LLM responses to thirty political prompts, we find that nearly all leading models are viewed as left-leaning, even by Democratic respondents, and that a simple tweak to system instructions measurably reduces this tilt. The method is readily transferable to any model, topic, or population, giving firms, regulators, and scholars a practical tool for monitoring—and mitigating—ideological distortion in an algorithmically curated information environment.
Three key findings:
- Models are slanted towards Democrats. This varies across models and across companies, but all have a left-leaning slant.
- A simple neutrality prompt decreases the perceived slant. This appears to be because the neutrality prompt causes the model to include more ambivalent words.
- LLMs do a poor job of assessing whether a human would perceive a response from a different LLM as biased.